


 PDF
PDFНаконец-то реализовал свой небольшой проект — разработал и опубликовал приложение для ОС Android справочник английских идиом под названием English idioms assistant. Ссылка на приложение в Google Play — https://play.google.com/store/apps/details?id=org.butorin.englishidiomsassistant.

Для начала напомню, идиома — это устойчивое выражение или оборот речи, значение которого не определяется входящими в его состав словами. Например, русское выражение: «спустя рукава», «как снег на голову» и т.д. В английском языке также есть аналогичные выражения, например, rain cats and dogs — льет как из ведра.
Приложение предоставляет следующие основные возможности:
- поиск по ключевым словам
- поиск внутри словарной статьи
- отмечать выражения в качестве избранных для быстрого доступа
- отправка выражений в другие приложения
- для каждого выражения доступна статья с описанием
- нет рекламы
- оффлайн база без необходимости Интернет-подключения
- оптимизировано для планшетов и телефонов
- языки интерфейса: Русский и Английский
Далее скрины программы и краткий ход разработки приложения.
![]()
Для каждого выражения полнота статьи может быть различной (этимология, описание значения, примеры использования, цитаты, перевод на другие языки). В качестве базы данных идиом использовались данные с Wiktionary (http://en.wiktionary.org/wiki/Category:English_idioms). Из базы удалены вульгарные выражения.
При открытии приложения отображается алфавитный список выражений.
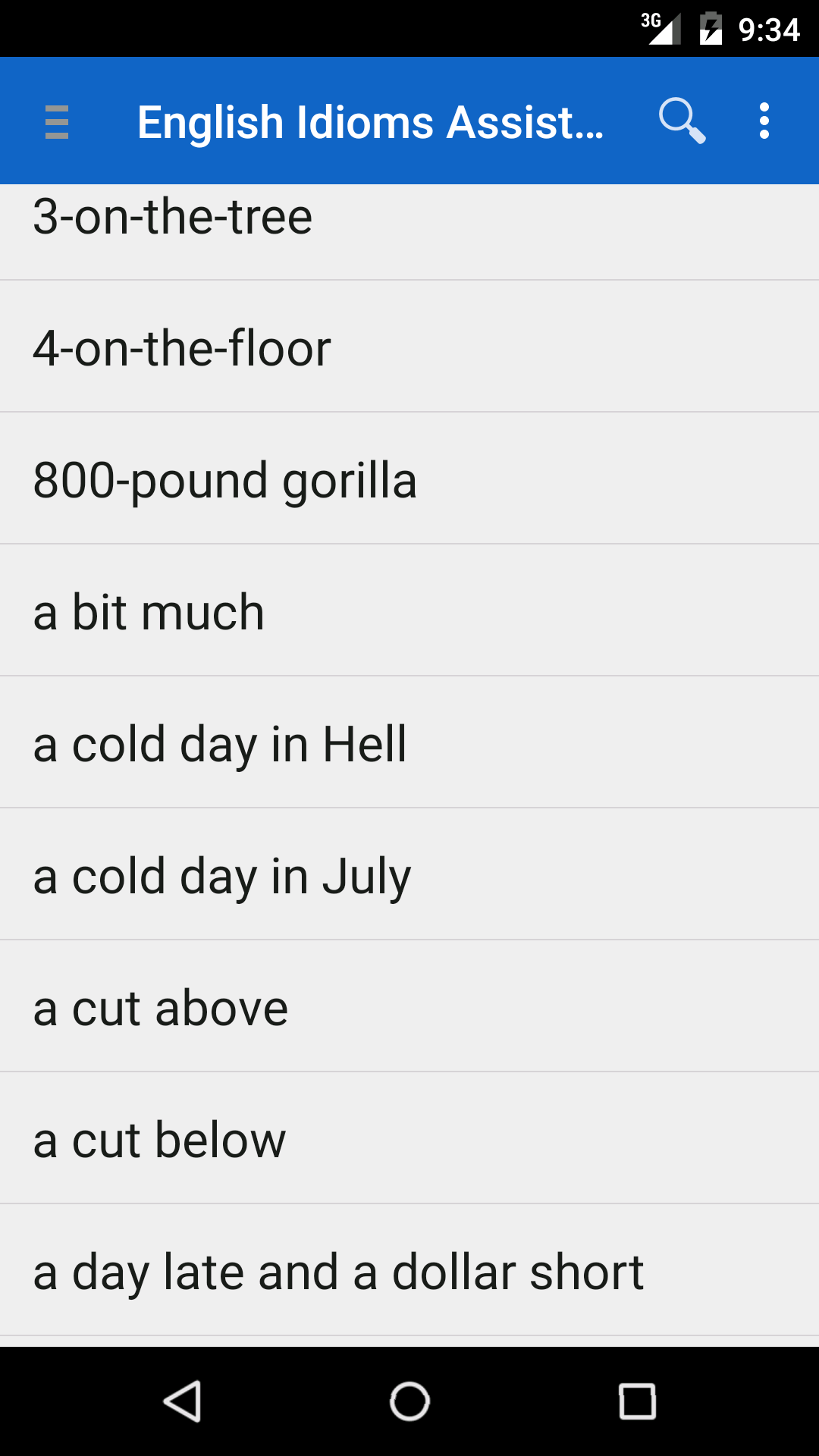
Рис. 1. Главный экран приложения English idioms assistant
Список подгружается динамически при прокручивании из локальной базы. В боковом меню есть доступ к полному списку идиом, к избранным выражениям, а также списку с ранее просмотренными фразами.
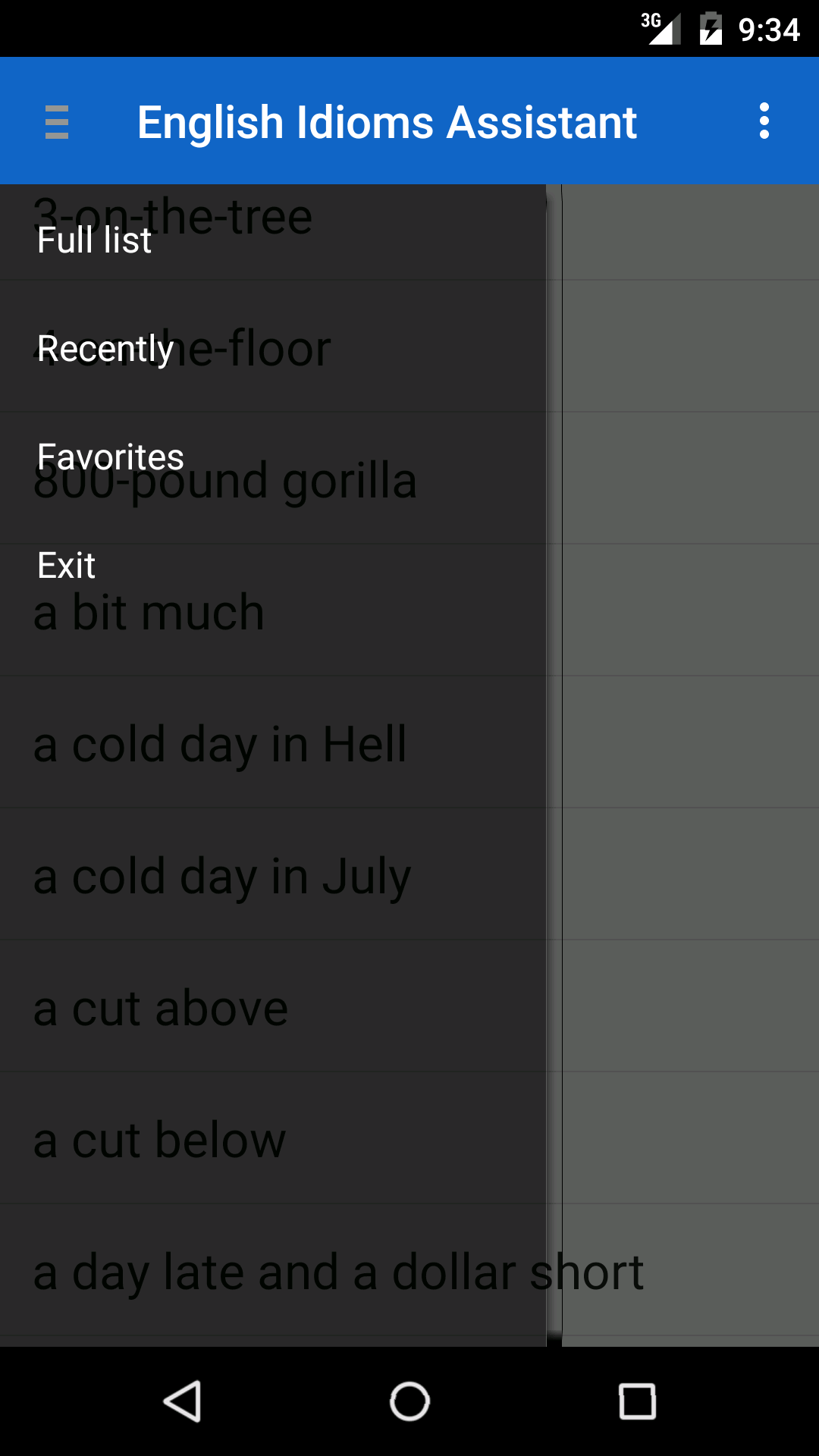
Рис. 2. Боковое меню приложения
При выборе некоторой фразы отображается исчерпывающая информация о ней. Как правило, это ее значение, примеры использования, этимология и варианты перевода на другие языки.

Рис. 3. Экран с описанием идиомы
Конечно, объем описания и количество включенных аспектов разнится в фразах. В некоторых есть большое описание, интересные варианты происхождения выражения (этимология), примеры использования, иногда и цитаты из книг, газет и фильмов. Другие же содержат лишь краткое описание. Это зависит от объема информации, представленной в Викисловаре (Wikitonary).
На экране с описанием выражения можно отметить идиому в избранное (кнопка со звездочкой) или отправить выражение (не описание) в другое приложение, например, отправить по e-mail, или, что более полезно отправить в LinguaLeo для дальнейшего повторения.
Реализован альбомный вид на планшетах в стиле Master-Details.

Рис. 4. Вид приложения на планшете
Просмотренные идиомы остаются в списке ранее просмотренных. Естественно, что оба списка — избранное и ранее просмотренных — можно легко очистить. Для этого следует воспользоваться соответствующими командами в основном меню.
А теперь несколько слов о том, как создавалось приложение. Сама идея пришла в конце октября 2014 года. Искал неплохое приложение с идиомами, но основные будущие конкуренты из топа либо содержали рекламу, либо представляли только краткое описание. Словарь идиом в одном из любимых моих приложений-словарей ABBYY Lingvo стоит чуть более 18$. Поэтому забавы ради, а также для получения бесценного опыта создания еще одного приложения решил написать нечто своё. То есть разработка планировалась just for fun.
Первым делом необходимо было решить, где получить базу выражений. В Сети много сайтов с английскими идиомами, собранными различными авторами. Естественно, что копировать у них выражения неприлично, да и не везде однотипно представлена информация. Вместе с этим нашел отличный раздел в Wikitonary с идиомами. Каждое выражение имеет различные разделы. Поэтому решил использовать именно эту базу, тем более ничего не мешает ее использовать в своих проектах при указании соответствующих ссылок на проект Викисловаря.
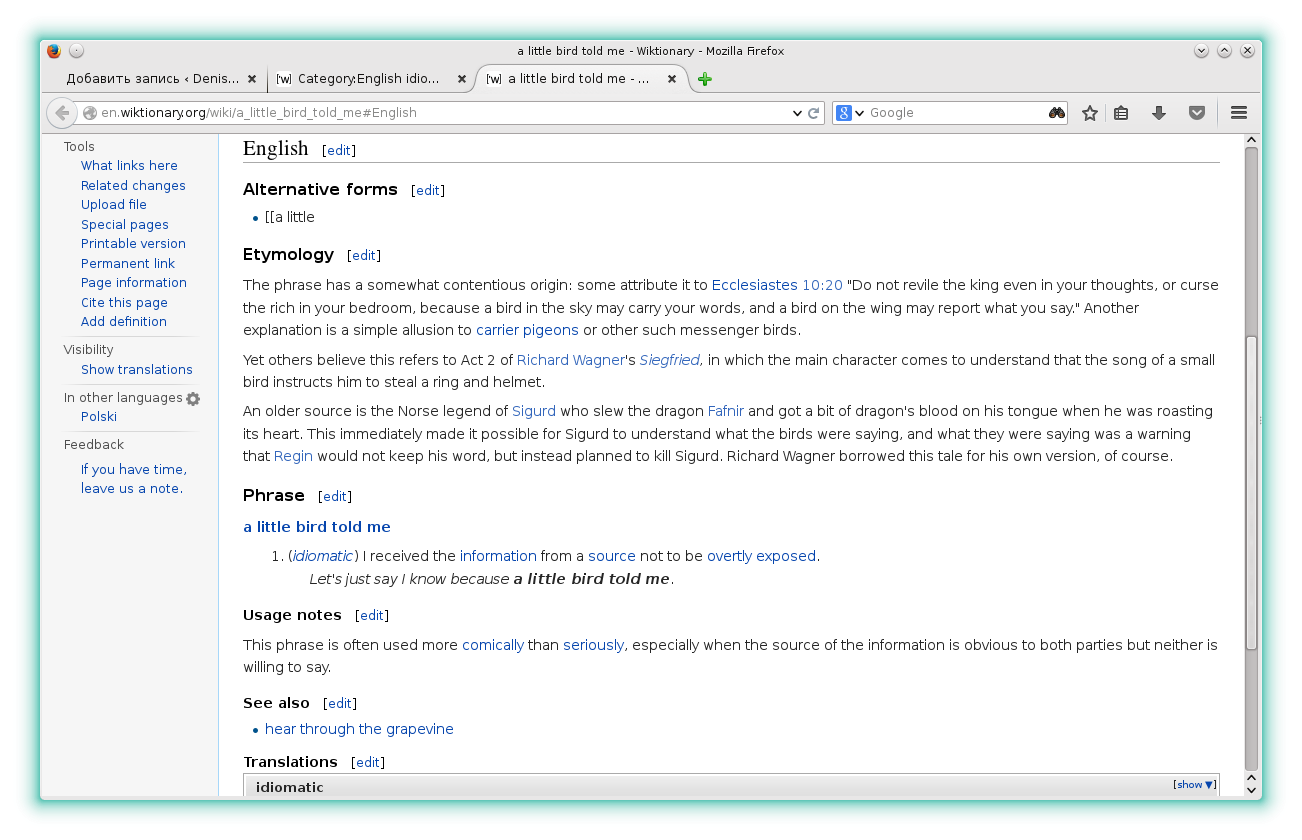
Рис. 5. Пример страницы с описанием идиомы в Викисловаре
Раз в качестве базы выбран Викисловарь, то второй задачей стал вопрос — «грабить» статьи сразу в html или в wikitext. За html было тезис — ничего не нужно конвертировать. Однако, просмотрев ряд идиом стало понятно, что html-разметка в статьях содержит множество ненужных ссылок и включает собственные ccs-стили. Поэтому принял решение получить из Викословаря статьи в формате wikitext, чтобы затем представить их более удобным на смартфоне/планшете образом. Так, скажем, в некоторых выражениях имеются ссылки на аудио файлы, часть разметки реализована колонками для чтения на экране монитора, используются спойлеры. Поэтому лучше иметь wikitext с парсером.
Решая эту задачу, создал небольшой консольный «паук», который используя API Викисловаря получил список всех идиом. Писал на Java в NetBeans 8. Для базы использовал сразу SQLite.

Рис. 6. NetBeans с фрагментом кода паука идиом
В итоге на рабочей машине со средней конфигурацией «два ядра, два гига и игровая видеокарта» и скоростью 8 Мбит/с список всех идиом был получен «паучком» за 2.5 часа.
Третья задача со звездочкой — это парсер wikitext. Поиск wiki-парсеров привел на страницу с великим множество парсеров для wikitext. Попробовав несколько из них, я увидел, что они слабо справляются с шаблонами Викисловаря. Либо получается плоский текст, максимум с заголовками первого-третьего уровня, либо получается нечитабельная, с точки зрения словаря, разметка множеством внешних ссылок без необходимых смещений право.
Стало понятно, что придется писать не только «паука» для граббинга идиом, но и парсер для преобразования wikitext из Викисловаря в нужный мне вариант html-разметки. Таким образом, пришлось разбираться с шаблонами Викисловаря. Не сказать, что их очень много, но каждый шаблон имеет множество вариантов использования. По мере изучения шаблонов и их использования в Викисловаре менялся алгоритм парсера. В итого пришел к тому, что следует сначала преобразовать все шаблоны, внутри которых не используются другие шаблоны, например, [[w …]] и другие. А затем искать, как я сам для себя определил, высокоуровневые шаблоны.
Таким образом, решая эту задачу был написан парсер и GUI для удобной верификации работы парсера. Опять-таки на Java в NetBeans 8.
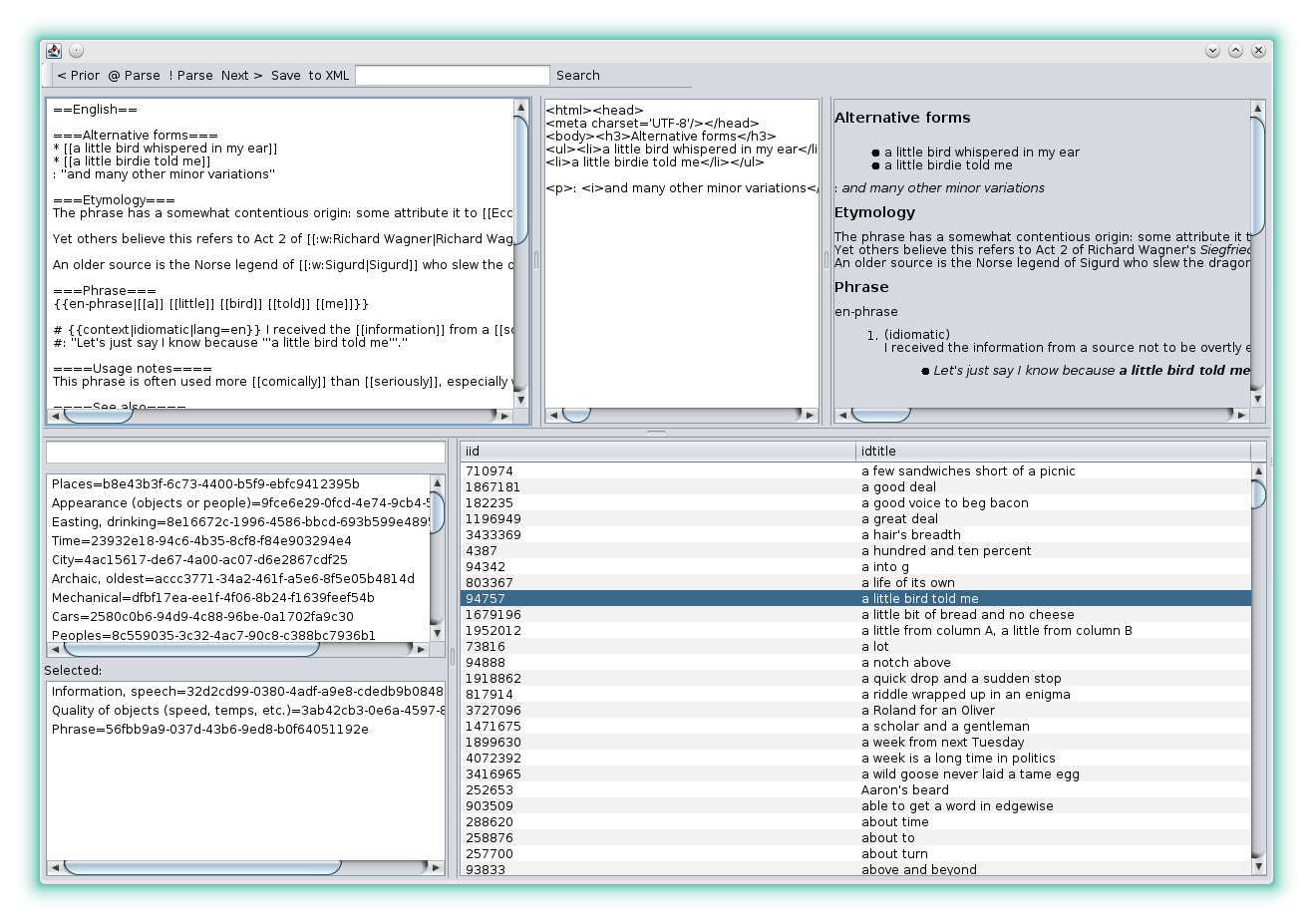
Рис. 7. Графический интерфейс парсера wikitext
В окне отображается оригинальная статья с wikitext, результат парсера в html и форматированный html. Естественно, что просматривать каждую статью нет сил и большого смысла. На это уходило бы более чем по 2 часа с учетом, что идиом ~8000, если просматривать их бегло в среднем по 10 сек. Соответственно в парсере учитывалось, если обнаруживается неизвестный шаблон или непонятная реализация существующего шаблона, то его пример записывается в лог.
При первых пробных запусках парсера после реализации основных простых шаблонов обнаруживалось более 60000 ошибок. Реализовав все шаблоны из списка Викисловаря удалось сначала сократить до 15К, затем до 5К и в итоге в актуальном варианте не более 500 непропарсенных шаблонов. Остальные 500 решил пока не исправлять, а оставить на потом, так как на разработку парсера и изучение шаблонов ушло достаточно много времени. Около месяца, если заниматься по паре часов вечерами и не каждый день. Понятно, что реализовать преобразование не так сложно, проблема в том, что вариантов использование шаблонов очень много, особенно, когда не знаешь какие могут быть варианты. Поэтому приходилось вносить изменения в парсер и прогонять его по базе. Прогон парсера по всей базе без записи результирующей html разметки в базу занимал 3-5 минут, поэтому также лишний раз не хотелось запускать проверку.
В конце данного этапа был запущен парсер с записью результирующей html-разметки в базу. Так за 15-20 мин было получено самое главное в данном мини-проекте — база данных идиом.
На скриншоте GUI-парсера можно заметить заготовку для маркировки тематики идиом. Сделал задел на будущее, проставить теги/темы для каждой идиомы, чтобы было удобно находить/подбирать выражение из темы.
Следующая, четвертая, задача — непосредственная разработка приложения. Писал в Eclipse на Java. Решил использовать совместимость с Android 2.2 (API v8), чтобы охватить большее число устройств, однако, то и дело возникали неудобства для реализации совместимости. Тем не менее, через несколько недель итогом работы напильником по вечерам получилось более-менее неплохое приложение.
Перед публикацией приложения возникла еще одна рутинная — пятая задача. В Google Play Маркет есть различные возрастные категории приложений. Просматривая идиомы в приложении стало понятно, что база содержит определенное количество вульгарных и неприличных выражений. Чтобы расширить аудиторию и понизить возрастные ограничения пришлось удалять эти самые непристойные выражения. Искать приходилось во разным ключевым словам и внимательно читать описание выражения. Иногда случалось так, что само выражение было безобидным и вполне юзабельным в приличном обществе. Однако, предложенные варианты перевода, особенно, на русском языке включали как приличные синонимы, так и непристойные. Например, act out — «выпендриваться». Ну, нет же, «наш человек» на Викисловаре потрудился (а вернее, не поленился) добавить целый ряд вариантов выражений с использованием ненормативной лексики. Спрашивается зачем? Поэтому статьи для таких выражений пришлось править, чтобы оставить их в базе. Кроме того, бывало выражение включало в раздел see also (см.также) похожие или синонимы, но среди них попадались удаленные вульгарные фразы. Так отсеялось около 500 выражений. Вообще занятие не из приятных, а достаточно нудных и рутинных. Поэтому, «не кидайтесь тяжелыми предметами», если вдруг что-то пропустил.
В завершении, быть может шестая задача, пару дней потратил на подготовку публикации — создание скринов, промо-изображения для Play Маркета и загрузки всех материалов в Google Play.
Теперь задача номер семь — хвастать друзьям и знакомым с легким намёком скачать и «откомментить» приложение, желательно с максимальным числом звезд 😉
Понимаю, что аналогичного софта очень много на Маркете и платных, и бесплатных, и со встроенными покупками, однако, надеюсь приложение найдет, пусть не большую, но свою аудиторию и кому-то будет удобно его использовать.
Комментарии и пожелания принимаются.
Благодарю всех, загрузивших приложение!