


 PDF
PDFЗадачи оптимизации распределения ресурсов при неполной информации встречаются в различных областях человеческой деятельности, потому что часто приходится решать такие задачи, где из некоторого набора вариантов решения нужно выбрать наиболее перспективные, удовлетворяющие определенным требованиям.
С такими проблемами специалисты-практики сталкиваются, решая, например, экономические, производственные и другие задачи, т.е. везде, где есть некоторое количество ресурсов, пунктов потребления этих ресурсов и сведения об эффективности от вложения ресурсов в определенные пункты.
Например, задача распределения ресурсов в производстве может иметь следующую формулировку. Имеется несколько различных катализаторов производственного процесса, стадии этого процесса и экспериментальные данные об эффекте, получаемом от вложения катализаторов. Нужно конкретное количество распределить по стадиям так, чтобы максимизировать эффективность производственного процесса, который может выражаться через количество продукции.
В экономической области на место ресурсов становятся денежные средства, на место пунктов вложения ‑ либо города, в которые вкладывают средства, либо сфера деятельности, либо конкретный товар. Эффективностью вложения при этом можно называть прибыль, получаемую от вложения средств.
Задача эксперта состоит в том, чтобы исследовать зависимость решения задачи от исходных данных. На основании набора экспериментальных данных он исследует и анализирует работу системы, и выбирает наиболее перспективные и максимально эффективные варианты решения задачи для того, чтобы их предоставить заказчику.
В условиях неполной информации эксперту предстоит изучать и анализировать систему. Для проведения многократных экспериментов необходимо имитировать реальную систему. Этот процесс называется имитационным моделированием.
Под имитацией системы понимается организация эксперимента, обеспечивающего логическую взаимосвязь свойств модели в соответствии с реальностью изучаемого процесса. Результаты имитации дополняют неполную информацию о начальных состояниях системы и ее входных воздействиях.
Постановка задачи
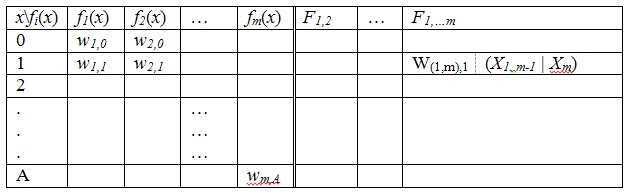
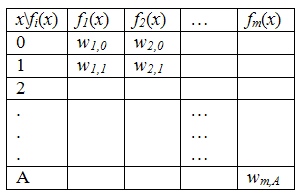
Пусть имеется некоторое количество ресурсов А, которое необходимо распределить по определенным пунктам назначения fi, где i = 1…m (m – количество объектов, куда распределяются ресурсы), и значения эффективности от вложения определенного количества ресурсов в i-ый пункт – fi(xi).
Показатели эффективностей задаются таблицей, которая представляет собой:
- объекты распределения ресурсов (по столбцам);
- объемы ресурсов, распределяемые на каждый пункт (по строкам);
- показатели эффективности системы от вложения ресурсов в определенные пункты назначения (на пересечении строк и столбцов).
|
fi x |
f1 |
f2 |
f3 |
fm |
|
0 |
||||
|
1 |
||||
|
2 |
||||
|
3 |
||||
|
А |
Требуется: распределить ресурсы между пунктами потребления таким образом, чтобы получить максимальный суммарный эффект от вложения ресурсов и, кроме того, получить набор наиболее перспективных вариант решения(если их будет несколько).
Математическая постановка задачи имеет вид:

Где
xi, – количество ресурсов, вкладываемое в i-ый пункт (изменяется xi = 0..A)
fi , i = 1…m – пункты назначения ресурсов;
fi (xi) , i =1…m – эффект от вложения количества xi ресурсов в fi пункт
А – общее количество ресурсов;
Данные задачи решаются с помощью метода динамического программирования (метод Беллмана).
Однако в жизни эксперт в предметной области не может предоставить точные данные о значениях эффектов. В основном доступны не статические значения эффектов, а определенные диапазоны значений, в котором они колеблются. В таком случае мы не можем решить задачу и вывести определенное значение максимальной эффективности и набор оптимальных решений, так как при различных наборах случайных значений эффективностей задача будет иметь разные оптимальные решения.
Для того, чтобы все-таки определить наиболее перспективные варианты решений, применяют методы имитационного моделирования, то есть используют алгоритмы для имитации поведения системы в жизненных условиях.
Рассуждая логически можно прийти к следующему выводу. Если решать задачу о распределении ресурсов и различном наборе случайных значений эффективностей, то мы будем получать различные значения максимального эффекта от вложения ресурсов. Повторяя операцию много раз, получим набор значений максимальных эффективностей при разных начальных условиях. Естественно, можно определить плотность распределения случайных величин, найти математическое ожидание, среднеквадратичное отклонение, а также доверительный интервал, в котором будут находиться наиболее перспективные решения. Причем, чем больше раз будем прогонять задачу, тем больше статистических данных соберем, тем точнее получатся выводы.
Подробно изобразим структуру имитационной модели оптимизации:
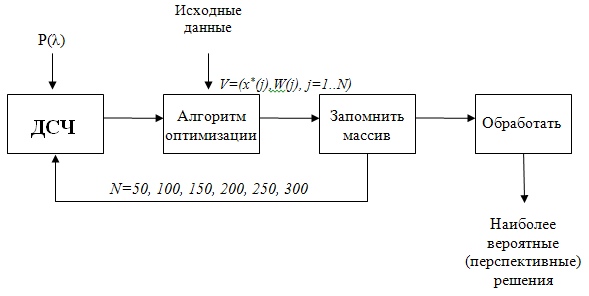
где
N – количество имитаций или объем выборки.
Рассмотрим модули структуры:
1. Отталкиваясь от того, что для моделирования требуется иметь случайные значения эффективностей, распределенные с определенными плотностями вероятности появления значений, то первый модуль схемы занимает датчик случайных чисел(ДСВ). Он генерирует необходимые случайные значения для конкретного прогона задачи и передает их следующему модулю.
2. Когда сгенерирован определенный вариант задачи, то можно ее решить используя те же алгоритмы решения. После этого мы получим набор оптимальных вариантов распределения ресурсов, конкретно для данного набора входных эффективностей.
Набор оптимальных вариантов распределения ресурсов:
Критерий эффективности:

Критерий W(j) показывает максимальный эффект от вложения j-ой комбинации распределения ресурсов.
Полученные данные передаются в следующий модуль.
3. Набор оптимальных решений и значения эффективности запоминаются, и запускается следующий прогон задачи, то есть генерируются новые случайные значения эффективностей и цикл повторяется снова.
4. Задача прогоняется по несколько раз, например, по 5 или 6 раз с 50 итераций до N(например, 300 или 600) можно также настроить шаг в 50 или 10 раз. После осуществления заданного числа итераций набор статистических данных отправляется на обработку.
5. На последнем шаге определяется небольшой набор наиболее перспективных вариантов, и они выдаются эксперту.
Алгоритм оптимизации
Задача решается с помощью метода динамического программирования.
Исходные данные:
Целевая функция:
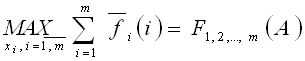
Нужно узнать, как распределить оптимально ресурсы между m-пунктом и всеми остальными:
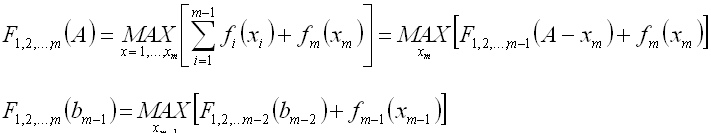
Так как на следующих уровнях распределение ресурсов неизвестно, то спускаемся до тех пор, пока не требуется распределение количества ресурсов между двумя первыми пунктами.
Распределение ресурсов по пунктам:
С помощью данной формулы находим варианты распределения ресурсов в количестве от 0 до b2 и эффективности такого вложения. После нахождения всех вариантов в каждой ячейке F1..m будут записаны эффективности от вложения ресурсов и набор вариантов распределения. Первая цифра означает, сколько ресурсов необходимо оставить на пункты 1..m-1, а вторая ‑ сколько оставить на m-пункт, чтобы получить данный эффект.
Затем можно найти распределение ресурсов между тремя пунктами назначения и так далее до m-пункта. Посчитав в конце F1,2…m(A) можно найти все оптимальные варианты, собрав их рекурсивно с последнего набора ответов.
Обработка результатов имитационного моделирования
Цель обработки результатов – выбор наиболее перспективных вариантов проекта, чтобы предоставить их заказчику.
Порядок действий:
1) Построить оценку плотности вероятности P(W).
1.1. В случае симметричных законов распределения и близких к нему.
Если она близка к симметричной, то наиболее вероятно среднее значение и оценку среднеквадратичного отклонения .
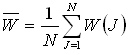
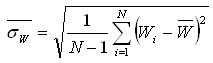
1.2. В случае несимметричных законов, найти моду (наиболее вероятное значение)
2) Построить доверительный интервал вокруг среднего значения(при близком к нормальному закону распределения) или вокруг моды(в случае не Гауссовых законов):
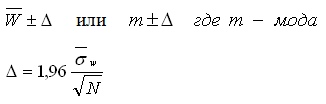
Наиболее вероятное решение будет принадлежать этому интервалу.
3) Найти Wср.ср. от количества прогонов. Например, задача прогоняется по 50 раз(N) 6 раз, тогда после каждых 50 итераций будем иметь одно среднее и после таких 6 этапов, соответственно, 6 средних значений. Значение Wср.ср. в данном случае будет равно среднему значению из 6 средних. При изменении N от 50 до 600 итераций получим совокупность значений Wср.ср., которые будем выводить на график зависимости Wср.ср. от N. Если график будет похож на график рисунка 1, то можно сделать вывод, что при увеличении числа прогонов система стремится к устойчивому состоянию.
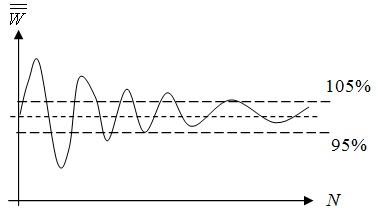
Подобные ухищрения обоснованы тем, что Wср.ср. остается пока случайной величиной, в то время как среднее значение Wср.ср. практически не изменяется. Поэтому можно сказать, что система будет стремиться к этому значению эффективности. При попадании амплитуды графика в 5% коридор говорят о получении достоверных данных, начиная с этого количества итераций.
4) Для оценки количества имитаций для попадания в заданный интервал ошибки при унимодальных и близких к нормальному закону распределения функций используется неравенство Чебышева.
Проверяем, как результат, полученный в ходе эксперимента, согласуется с неравенством Чебышева:

Задаем необходимое отклонение β, точность e и находим количество итераций, которые необходимо проделать.
Количество итераций, при котором значение эффективности попадает в заданный коридор на графике Wср.ср. от N должно соответствовать неравенству Чебышева.
В следующей заметке представлю приложение, которое реализует данный алгоритм имитационного моделирования.